Multimodal: Images, Audio, and Speech
Source:vignettes/multimodal-images-audio-speech.Rmd
multimodal-images-audio-speech.RmdTranscribe interviews and podcasts
hf_transcribe() accepts a local audio path, URL, or raw
vector and returns a tibble with transcript text. Set
return_timestamps = "word" when the model supports
word-level chunks.
audio <- "https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac"
transcript <- hf_transcribe(audio, return_timestamps = "word")
transcript$text
#> [1] " I have a dream that one day this nation will rise up and live out the true meaning of its creed."
transcript$chunks[[1]]
#> [[1]]
#> [[1]]$text
#> [1] " I"
#>
#> [[1]]$timestamp
#> [[1]]$timestamp[[1]]
#> [1] 0
#>
#> [[1]]$timestamp[[2]]
#> [1] 1.1
#>
#>
#>
#> [[2]]
#> [[2]]$text
#> [1] " have"
#>
#> [[2]]$timestamp
#> [[2]]$timestamp[[1]]
#> [1] 1.1
#>
#> [[2]]$timestamp[[2]]
#> [1] 1.44
#>
#>
#>
#> [[3]]
#> [[3]]$text
#> [1] " a"
#>
#> [[3]]$timestamp
#> [[3]]$timestamp[[1]]
#> [1] 1.44
#>
#> [[3]]$timestamp[[2]]
#> [1] 1.62
#>
#>
#>
#> [[4]]
#> [[4]]$text
#> [1] " dream"
#>
#> [[4]]$timestamp
#> [[4]]$timestamp[[1]]
#> [1] 1.62
#>
#> [[4]]$timestamp[[2]]
#> [1] 1.92
#>
#>
#>
#> [[5]]
#> [[5]]$text
#> [1] " that"
#>
#> [[5]]$timestamp
#> [[5]]$timestamp[[1]]
#> [1] 1.92
#>
#> [[5]]$timestamp[[2]]
#> [1] 3.7
#>
#>
#>
#> [[6]]
#> [[6]]$text
#> [1] " one"
#>
#> [[6]]$timestamp
#> [[6]]$timestamp[[1]]
#> [1] 3.7
#>
#> [[6]]$timestamp[[2]]
#> [1] 3.88
#>
#>
#>
#> [[7]]
#> [[7]]$text
#> [1] " day"
#>
#> [[7]]$timestamp
#> [[7]]$timestamp[[1]]
#> [1] 3.88
#>
#> [[7]]$timestamp[[2]]
#> [1] 4.24
#>
#>
#>
#> [[8]]
#> [[8]]$text
#> [1] " this"
#>
#> [[8]]$timestamp
#> [[8]]$timestamp[[1]]
#> [1] 4.24
#>
#> [[8]]$timestamp[[2]]
#> [1] 5.82
#>
#>
#>
#> [[9]]
#> [[9]]$text
#> [1] " nation"
#>
#> [[9]]$timestamp
#> [[9]]$timestamp[[1]]
#> [1] 5.82
#>
#> [[9]]$timestamp[[2]]
#> [1] 6.78
#>
#>
#>
#> [[10]]
#> [[10]]$text
#> [1] " will"
#>
#> [[10]]$timestamp
#> [[10]]$timestamp[[1]]
#> [1] 6.78
#>
#> [[10]]$timestamp[[2]]
#> [1] 7.36
#>
#>
#>
#> [[11]]
#> [[11]]$text
#> [1] " rise"
#>
#> [[11]]$timestamp
#> [[11]]$timestamp[[1]]
#> [1] 7.36
#>
#> [[11]]$timestamp[[2]]
#> [1] 7.88
#>
#>
#>
#> [[12]]
#> [[12]]$text
#> [1] " up"
#>
#> [[12]]$timestamp
#> [[12]]$timestamp[[1]]
#> [1] 7.88
#>
#> [[12]]$timestamp[[2]]
#> [1] 8.46
#>
#>
#>
#> [[13]]
#> [[13]]$text
#> [1] " and"
#>
#> [[13]]$timestamp
#> [[13]]$timestamp[[1]]
#> [1] 8.46
#>
#> [[13]]$timestamp[[2]]
#> [1] 9.2
#>
#>
#>
#> [[14]]
#> [[14]]$text
#> [1] " live"
#>
#> [[14]]$timestamp
#> [[14]]$timestamp[[1]]
#> [1] 9.2
#>
#> [[14]]$timestamp[[2]]
#> [1] 10.34
#>
#>
#>
#> [[15]]
#> [[15]]$text
#> [1] " out"
#>
#> [[15]]$timestamp
#> [[15]]$timestamp[[1]]
#> [1] 10.34
#>
#> [[15]]$timestamp[[2]]
#> [1] 10.58
#>
#>
#>
#> [[16]]
#> [[16]]$text
#> [1] " the"
#>
#> [[16]]$timestamp
#> [[16]]$timestamp[[1]]
#> [1] 10.58
#>
#> [[16]]$timestamp[[2]]
#> [1] 10.8
#>
#>
#>
#> [[17]]
#> [[17]]$text
#> [1] " true"
#>
#> [[17]]$timestamp
#> [[17]]$timestamp[[1]]
#> [1] 10.8
#>
#> [[17]]$timestamp[[2]]
#> [1] 11.04
#>
#>
#>
#> [[18]]
#> [[18]]$text
#> [1] " meaning"
#>
#> [[18]]$timestamp
#> [[18]]$timestamp[[1]]
#> [1] 11.04
#>
#> [[18]]$timestamp[[2]]
#> [1] 11.4
#>
#>
#>
#> [[19]]
#> [[19]]$text
#> [1] " of"
#>
#> [[19]]$timestamp
#> [[19]]$timestamp[[1]]
#> [1] 11.4
#>
#> [[19]]$timestamp[[2]]
#> [1] 11.64
#>
#>
#>
#> [[20]]
#> [[20]]$text
#> [1] " its"
#>
#> [[20]]$timestamp
#> [[20]]$timestamp[[1]]
#> [1] 11.64
#>
#> [[20]]$timestamp[[2]]
#> [1] 11.8
#>
#>
#>
#> [[21]]
#> [[21]]$text
#> [1] " creed."
#>
#> [[21]]$timestamp
#> [[21]]$timestamp[[1]]
#> [1] 11.8
#>
#> [[21]]$timestamp[[2]]
#> NULLTranscripts are ordinary text, so you can pipe them into other package features:
hf_extract(
transcript$text,
c(speaker_goal = "string", topic = "string"),
max_tokens = 100
)
#> # A tibble: 1 × 2
#> speaker_goal topic
#> <chr> <chr>
#> 1 <NA> <NA>Generate images
hf_text_to_image() writes generated images to disk and
also returns the raw bytes in a list-column.
dir.create("figures", showWarnings = FALSE)
img <- hf_text_to_image(
"a small red cube on a white background",
output = "figures/multimodal-red-cube.jpg",
seed = 1,
num_inference_steps = 2,
guidance_scale = 0,
overwrite = TRUE
)
tibble::tibble(
content_type = img$content_type,
bytes = length(img$image[[1]]),
file_exists = file.exists(img$path)
)
#> # A tibble: 1 × 3
#> content_type bytes file_exists
#> <chr> <int> <lgl>
#> 1 image/jpeg 26383 TRUE
knitr::include_graphics("figures/multimodal-red-cube.jpg")
Classify, caption, and detect objects
Image inputs can be URLs, local paths, or raw vectors. The examples below use a widely used image from the MS COCO validation set.
image <- "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/cats.png"
hf_classify_image(image, top_k = 3)
#> # A tibble: 3 × 3
#> image label score
#> <chr> <chr> <dbl>
#> 1 https://huggingface.co/datasets/huggingface/documentation-images/… tabb… 0.277
#> 2 https://huggingface.co/datasets/huggingface/documentation-images/… tige… 0.276
#> 3 https://huggingface.co/datasets/huggingface/documentation-images/… Egyp… 0.140
boxes <- hf_detect_objects(image, threshold = 0.5) |>
filter(label == "cat")
boxes
#> # A tibble: 2 × 7
#> image label score xmin ymin xmax ymax
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 https://huggingface.co/datasets/huggingfa… cat 0.997 156 31 385 146
#> 2 https://huggingface.co/datasets/huggingfa… cat 0.999 145 132 429 341Captioning uses a vision-capable chat model and may be subject to live provider capacity. Run it when the model/provider is available:
hf_caption_image(image, max_tokens = 40, temperature = 0)Bounding-box output is numeric and ready for visualization.
library(ggplot2)
ggplot(boxes) +
geom_rect(aes(xmin = xmin, ymin = ymin, xmax = xmax, ymax = ymax),
fill = NA, color = "red") +
geom_text(aes(x = xmin, y = ymin, label = label),
hjust = 0, vjust = 1, color = "red") +
coord_equal()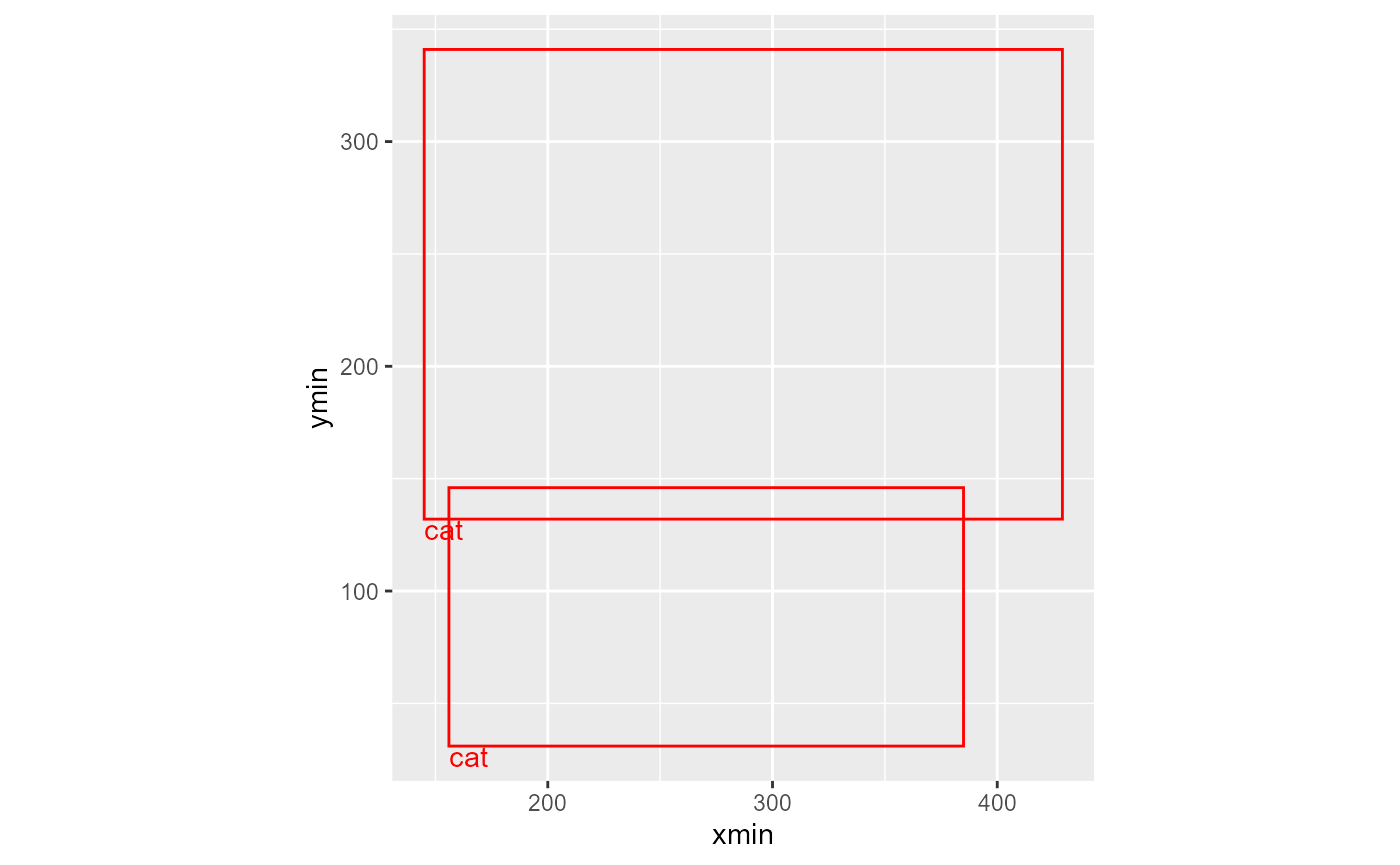
Text to speech
hf_text_to_speech() has the same file-output contract as
hf_text_to_image(), but public hosted TTS model
availability varies. During verification, beginner-friendly TTS
candidates were not supported by the public hf-inference
provider. Use a compatible provider suffix or dedicated Inference
Endpoint when available.
hf_text_to_speech(
"Hello from R.",
endpoint_url = "https://your-tts-endpoint.endpoints.huggingface.cloud"
)